
Directive pipeline
Directives are placed in a pipeline, and executed in order. Their initial design is simple, like this:

In this architecture:
- The input to the pipeline is the field's value provided by the field resolver
- Each directive performs its logic and passes the result to the next directive in the pipeline
- The pipeline's output will be the resolved field value, having been processed by all the directives
This architecture, though, doesn't make the most out of GraphQL. Below is the description of all the stages from the actual directive pipeline, until reaching the actual design implemented in Gato GraphQL.
Directives as building-blocks of the query resolution
Initially we could consider having the GraphQL server resolve the field through some mechanism, and then pass this value as input to the directive pipeline.
However, it is much simpler to have a single mechanism to tackle everything: invoking the field resolvers (to both validate fields and resolve fields) can be already done through the directive pipeline. In this case, the directive pipeline is the single mechanism used to resolve the query.
For this reason, the Gato GraphQL server is provided with two special directives:
@validatecalls the field resolver to validate that the field can be resolved (eg: the syntax is correct, the field exists, etc)- If successful,
@resolveValueAndMergethen calls the field resolver to resolve the field, and merges the value into the response object
These two are of the special type "system" directives: they are reserved to the GraphQL engine only, and they are implicit on every field. (In contrast, standard directives are explicit: they are added to the query by the user.)
By using these two directives, this query:
query {
field1
field2 @directiveA
}...will be resolved as this one:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}The pipeline now looks like this (please notice that the pipeline receives the field as input, and not its initial resolved value):

Pipeline slots
Directives are normally executed after @resolveValueAndMerge, since they most likely involve updating the value of the resolved field. However, there are other directives that must be executed before @validate, or between @validate and @resolveValueAndMerge.
For instance:
- In order to measure the time taken to resolve a field, directive
@traceExecutionTimecan obtain the current time before and after the field is resolved, by placing subdirectives@startTracingExecutionTimeat the beginning and@endTracingExecutionTimeat the end of the pipeline - A directive
@cachemust check if a requested field is cached and return this response already, before executing@resolveValueAndMerge
The pipeline will then offer five different slots through class PipelinePositions, and the directive will indicate in which one it must be executed:
- The
"beginning"slot: at the very beginning - The
"before-validate"slot: before the validation takes place - The
"middle"slot: after the validation and before the field resolution - The
"after-resolve"slot: after the field resolution - The
"end"slot: at the very end
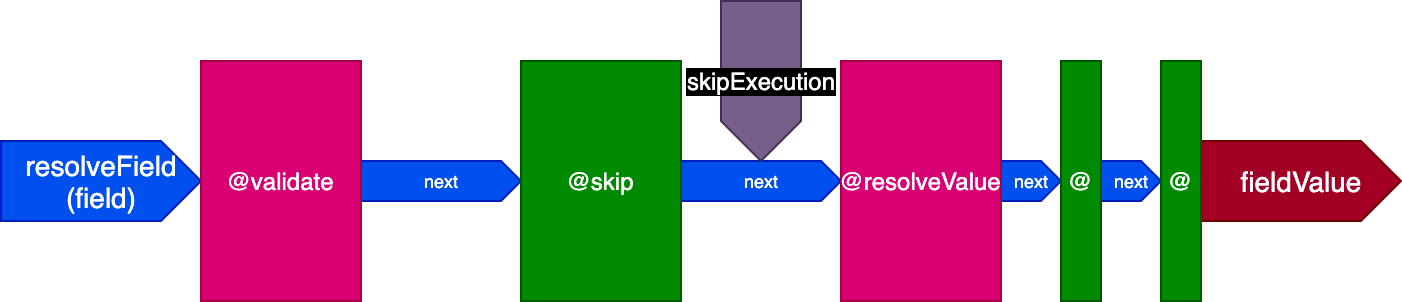
The directive pipeline now looks like this (considering just 3 stages, to simplify):

Please notice how directives @skip and @include can be so easily satisfied given this architecture: placed in the "middle" slot, they can inform directive @resolveValueAndMerge (along with all directives in later stages in the pipeline) to not execute by setting flag skipExecution to true.
Executing the directive on multiple fields in a single call
Until now, we have considered a single field being input to the directive pipeline. However, in a typical GraphQL query, we will receive several fields on which to execute directives.
For instance, in the query below, directive @upperCase is executed on fields "field1" and "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Moreover, since the GraphQL engine adds system directives @validate and @resolveValueAndMerge to every field in the query, so that this query:
query {
field1
field2
field3
}...is resolved as this query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Then, the system directives will always receive all the fields as inputs.
As a consequence, the directive pipeline is architected to receive multiple fields as input, and not just one at a time:

This architecture is more efficient, because executing a directive only once for all fields is faster than executing it once per field, and it will produce the same results.
For instance, when validating if the user is logged-in to grant access to the schema, the operation can be executed only once. Running the following code:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}is more efficient than running this code:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}This may not seem to be a big deal when calling a local function such as isUserLoggedIn, however it can make a big difference when interacting with external services, such as when resolving REST endpoints through GraphQL. In these cases, executing a function once instead of multiple times could make the difference between being able to provide a certain functionality or not.
Let's see an example. When interacting with Google Translate through a @translate directive, the GraphQL API must establish a connection over the network. Then, executing this code will be as fast as it can ever be:
googleTranslateFields([$field1, $field2, $field3]);In contrast, executing the function separately, multiple times, will produce a higher latency that will result in a higher response time, degrading the performance of the API. Possibly this is not a big difference for translating 3 strings (where the field is the string to be translated), but for 100 or more strings it will certainly have an impact:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Additionally, executing a function once with all inputs may produce a better response than executing the function on each field independently. Using Google Translate again as example, the translation will be more precise the more data we provide to the service.
For instance, when execute the code below:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");For the first independent execution, Google doesn't know the context for "fork", so it may well reply with fork as a utensil for eating, as a road branching out, or as another meaning. However, if we execute instead:
googleTranslate(["fork", "road", "sign"]);From this broader amount of information, Google can deduce that "fork" refers to the branching of the road, and return a precise translation.
It is for these reasons that the directives in the pipeline receive the input fields all together, and then each directive can decide the best way to run its logic on these inputs (a single execution per input, a single execution comprising all inputs, or anything in between).
The pipeline now looks like this:
Executing a single directive pipeline for the whole query
Just now we learnt that it makes sense to execute multiple fields per directive, however this works well as long as all fields have the same directives applied on them. When the directives are different, it can lead to a greater complexity that makes its implementation difficult, and would reduce some of the gained benefits.
Let's see how this happens. Consider the following query:
query {
field1 @directiveA
field2
field3
}This directive is equivalent to this one:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}In this scenario, fields field2 and field3 have the same set of directives, and field1 has a different one, then we would have to generate 2 different pipelines to resolve the query:
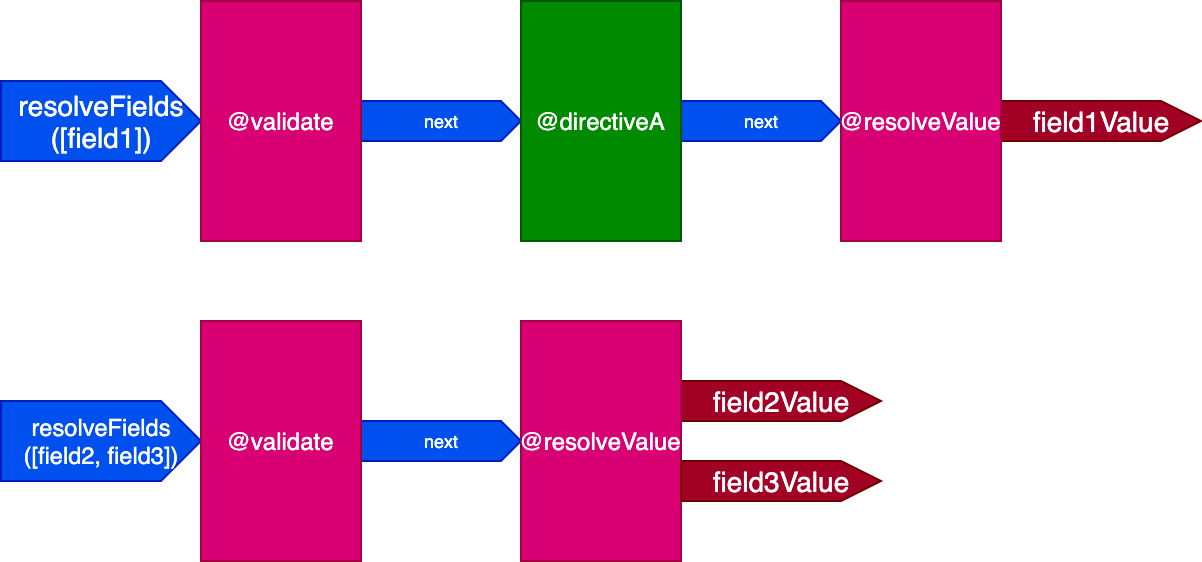
And when all fields have a unique set of directives, the effect is more pronounced. Consider this query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Which is equivalent to this:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}In this situation, we will have 3 pipelines to handle 3 fields, like this:
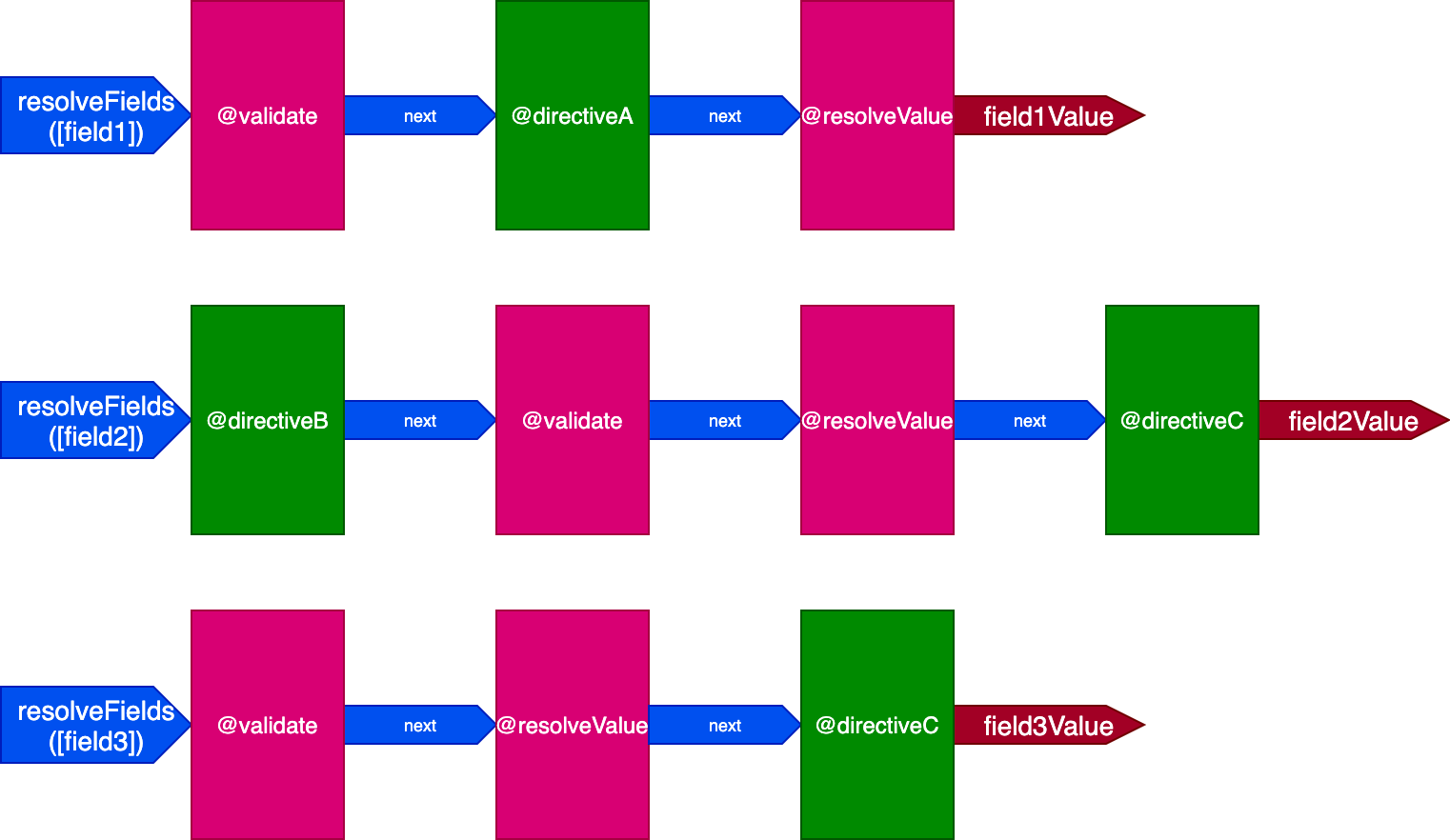
In this case, even though directives @validate and @resolveValueAndMerge are applied on the 3 fields, because they are executed through 3 different directive pipelines, then they will be executed independently of each other, which takes us back to having a directive being executed on a single item at a time.
The solution to this problem is to avoid producing multiple pipelines, but deal with a single pipeline for all the fields. As a consequence, the engine doens't pass the fields as input to the pipeline any longer, since not all directives from a single pipeline will interact with the same set of fields; instead, every directive must receive its own list of fields, as its own input.
Then, for this query:
query {
field1 @directiveA
field2
field3
}...directives @validate and @resolveValueAndMerge will get all 3 fields as inputs, and directiveA will only get "field1":
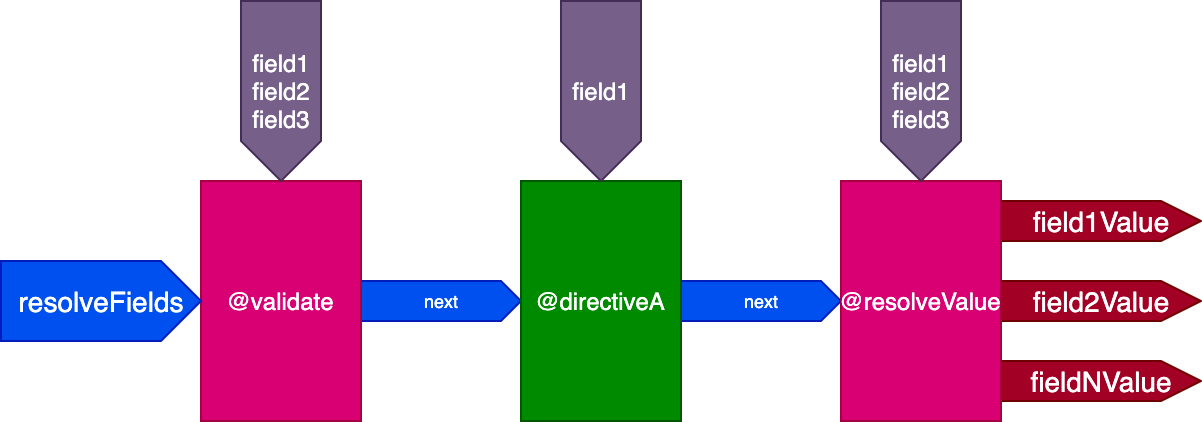
And for this query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...directives @validate and @resolveValueAndMerge will get all 3 fields as inputs, directiveA will only get "field1", directiveB will only get "field2", and directiveC will get "field2" and "field3":
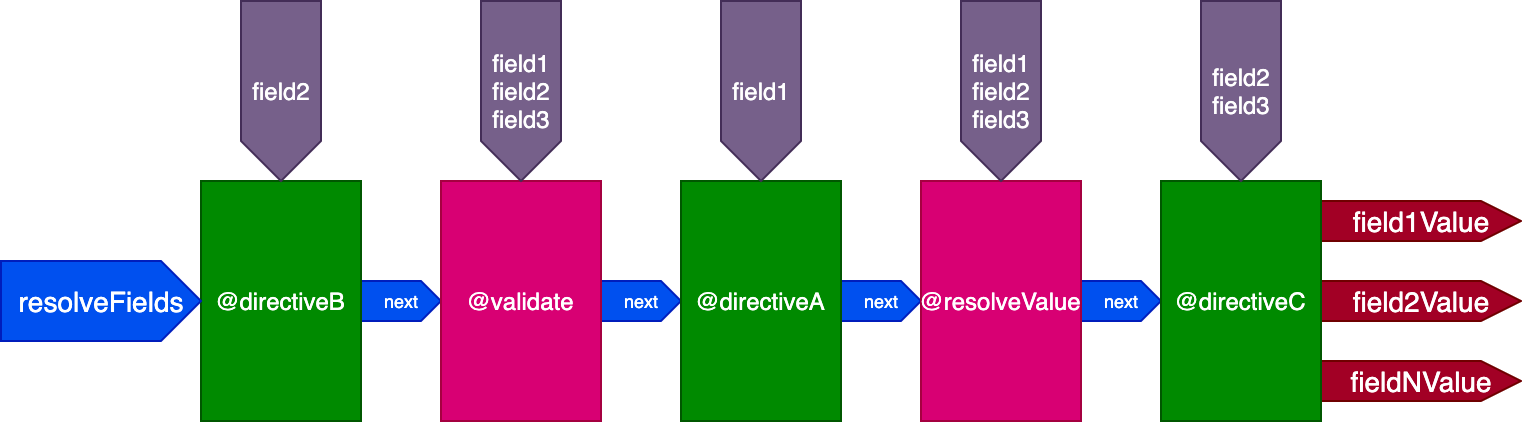
Controlling the directive execution ID by ID
Until now, a directive at some stage could influence the execution of directives at later stages through some flag skipExecution. However, this flag is not granular enough for all cases.
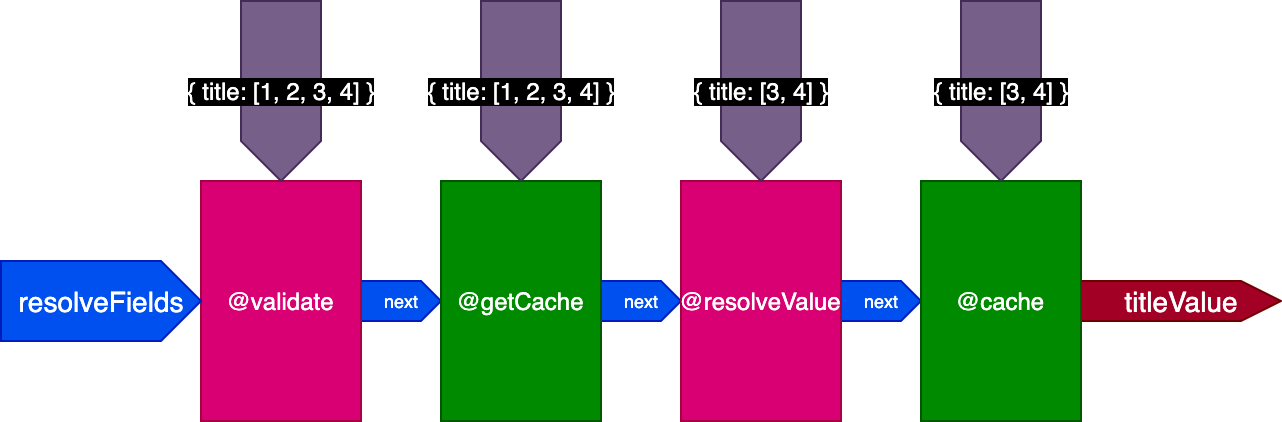
For instance, consider a @cache directive, which is placed in the "end" slot to store the field value, so that next time the field is queried, its value can be retrieved from the cache through a directive @getCache placed in the "middle" slot:
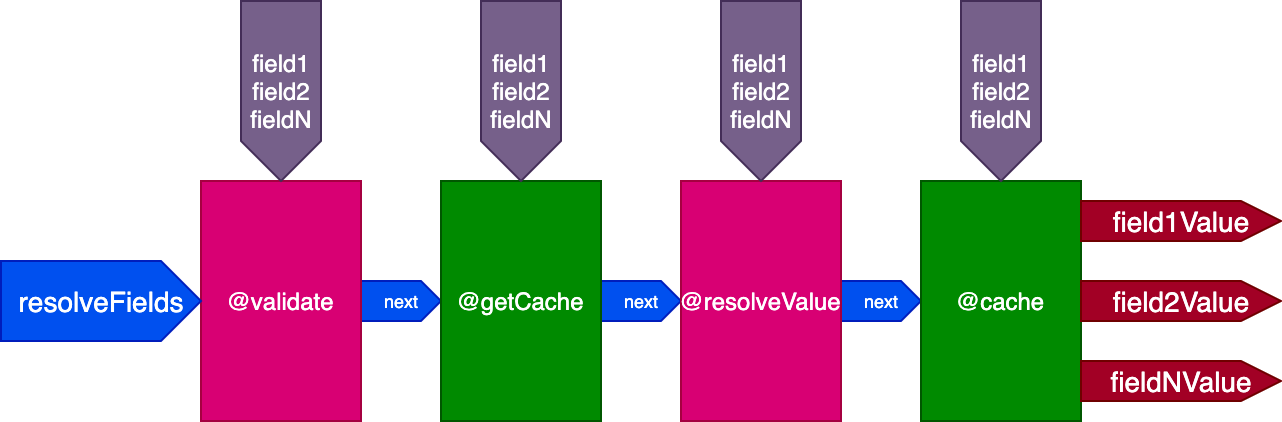
When executing this query:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}The server will retrieve and cache 2 records. Then, we execute the same query, but applied to 4 records:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}When executing this 2nd query, the 2 records from the 1st query were already cached, but the other 2 records were not. However, we would need all 4 records to be already cached in order to use flag skipExecution. It would be better if we could retrieve the first 2 records from the cache, and resolve only the 2 other records.
So we update the design of the pipeline again. We dump the skipExecution flag, and instead pass to each directive the list of object IDs per field where the directive must be applied, through a fieldIDs object input:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}Variable fieldIDs is unique to each directive, and every directive can modify the instance of fieldIDs for all directives at later stages. Then, skipExecution can be done granularly at an ID by ID basis, by simply removing the ID from fieldIDs for all upcoming directives in the stack.
The pipeline now looks like this:
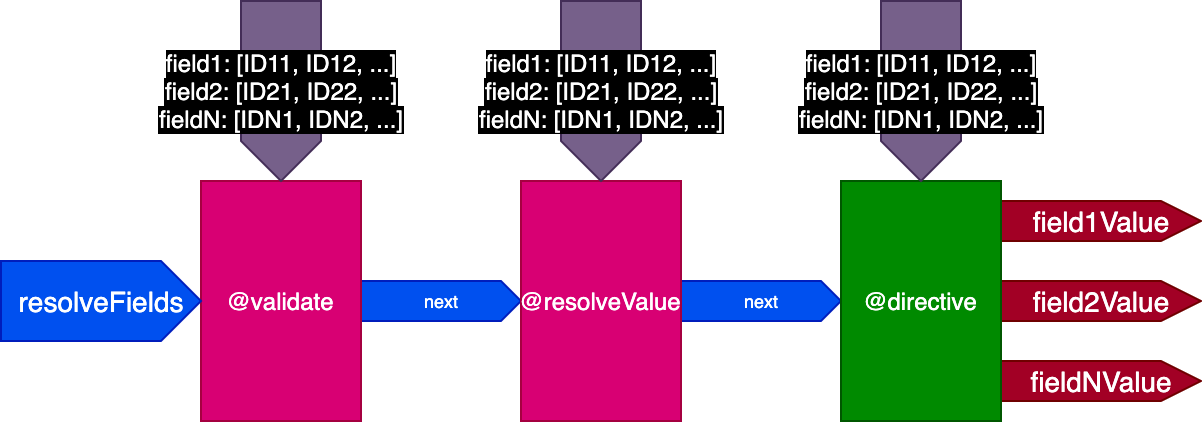
Applied to the previous example, when executing the first query translating 2 records, the pipeline looks like this:
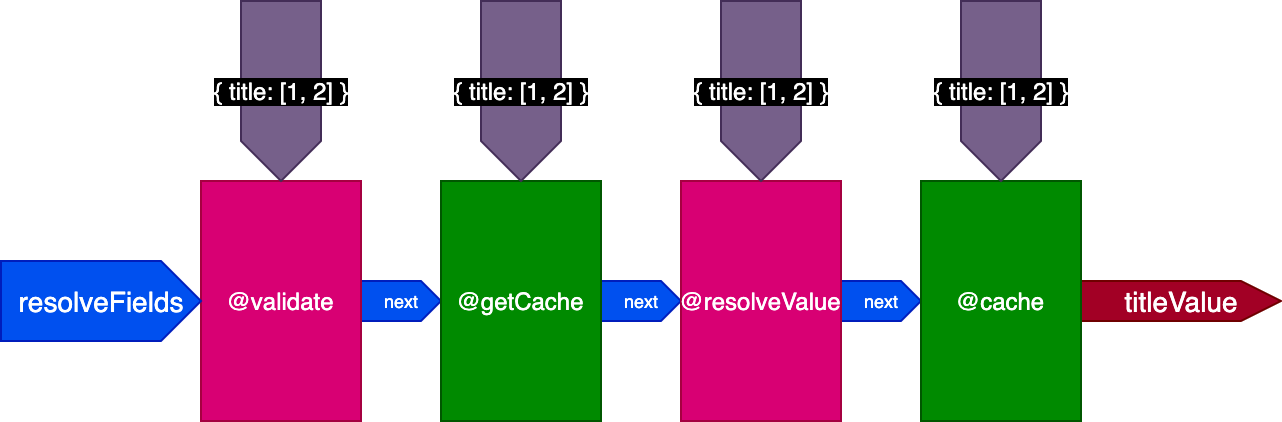
When executing the second query translating 4 records, directive @getCache gets the IDs for all 4 records, but both @resolveValueAndMerge and @cache will only receive the IDs for the last 2 records only (which are not cached):
Tying it all together
This is the final design of the directive pipeline:
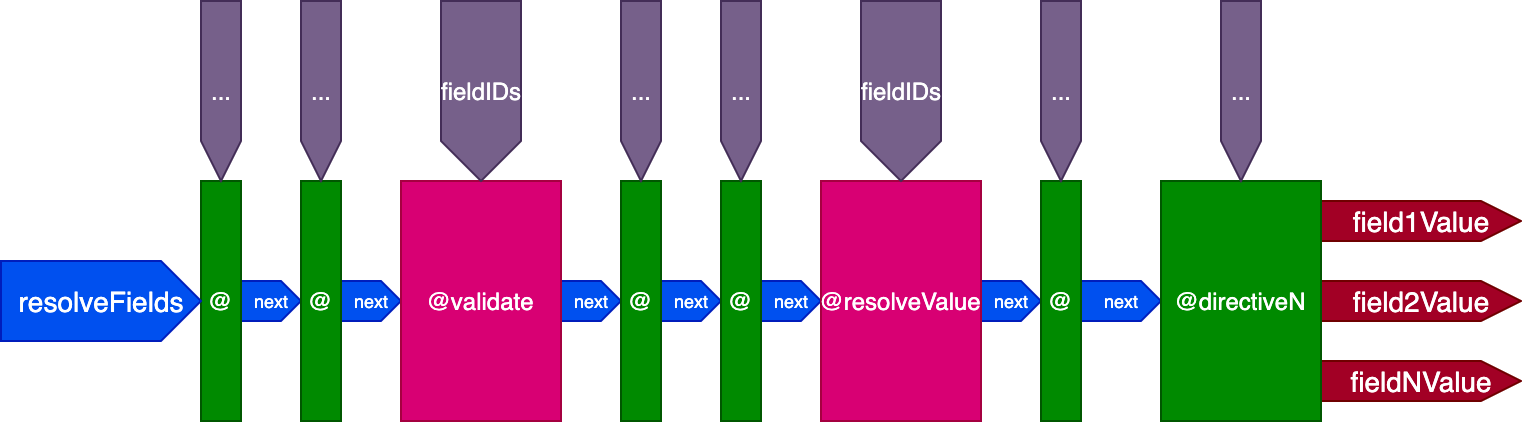
Summarizing, these are its characteristics:
- Field resolvers are invoked from within the directive pipeline, through directives
@validateand@resolveValueAndMerge - Directives can be placed on any of 5 slots:
"beginning","before-validate","middle","after-validate", and"end" - Directives resolve multiple fields in a single call
- A single pipeline contains all directives involved in the query
- Each directive receives its own set of IDs to resolve per field through variable
fieldIDs - Directives can modify variable
fieldIDsfor all directives at a later stage in the pipeline