
Dataloading engine
Gato GraphQL uses server-side components to represent the data model (not graphs or trees). Let's see how it executes the data-loading process to resolve the GraphQL query.
In order to process the data, we must flatten the components into types (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), order them as they appeared in the component hierarchy (Director, then Film, then Actor) and deal with them in "iterations", retrieving the object data for each type on its own iteration, like this:

The server's data-loading engine must implement the following (pseudo-)algorithm to load the data:
Preparation:
- Prepare an empty queue to store the list of IDs from the objects that must be fetched from the database, organized by type (each entry will be:
[type => list of IDs]) - Retrieve the ID of the featured director object, and place it on the queue under type
Director
Loop until there are no more entries on the queue:
- Get the first entry from the queue: the type and list of IDs (eg:
Directorand[2]), and remove this entry off the queue - Using the type's
TypeDataLoaderobject, execute a single query against the database to retrieve all objects for that type with those IDs - If the type has relational fields (eg: type
Directorhas relational fieldfilmsof typeFilm), then collect all the IDs from these fields from all the objects retrieved in the current iteration (eg: all IDs in fieldfilmsfrom all objects of typeDirector), and place these IDs on the queue under the corresponding type (eg: IDs[3, 8]under typeFilm).
By the end of the iterations, we will have loaded all the object data for all types, like this:
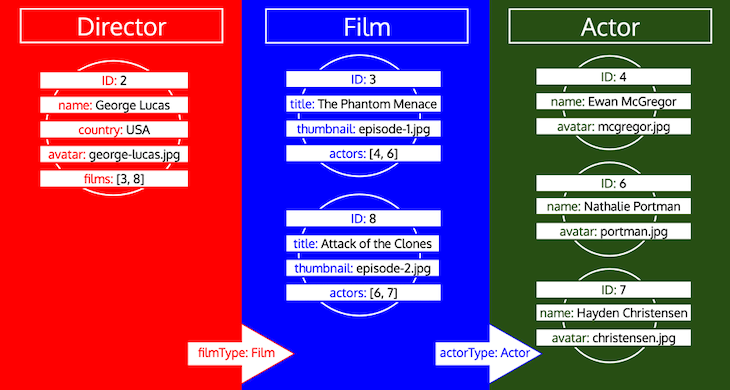
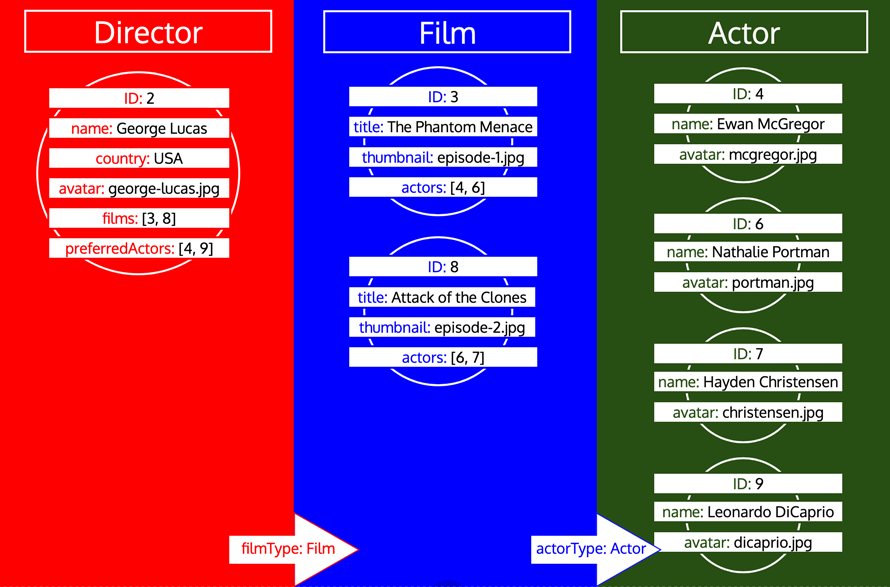
Please notice how all IDs for a type are collected, until the type is processed in the queue. If, for instance, we add a relational field preferredActors to type Director, these IDs would be added to the queue under type Actor, and it would be processed together with the IDs from field actors from type Film:
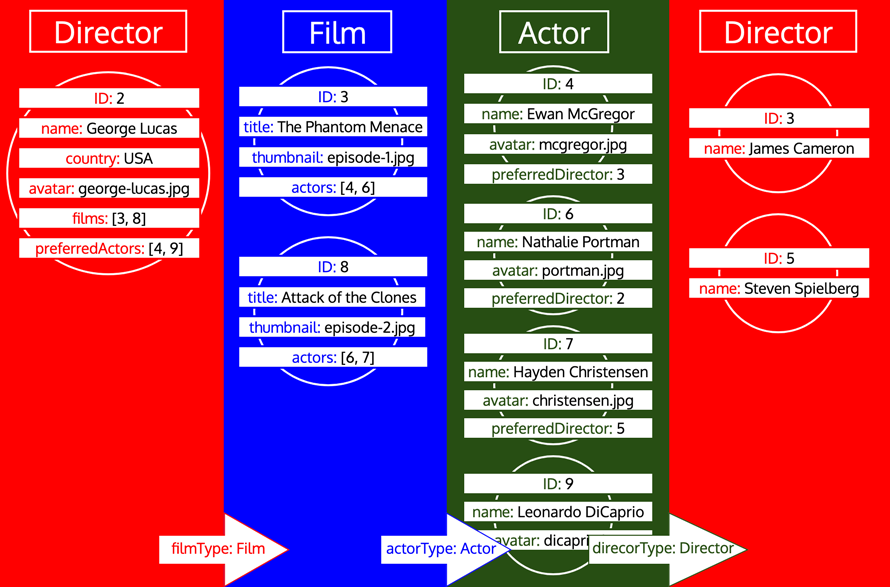
However, if a type has been processed and then we need to load more data from that type, then it's a new iteration on that type. For instance, adding a relational field preferredDirector to the Author type, will make the type Director be added to the queue once again:
Now that we have fetched all the object data, we need to shape it into the expected response, mirroring the GraphQL query. However, as it can be seen, the data does not have the required tree structure. Instead, relational fields contain the IDs to the nested object, emulating how data is represented in a relational database. Hence, following this comparison, the data retrieved for each type can be represented as a table, like this:
Table for type Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Table for type Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Table for type Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Having all the data organized as tables, and knowing how every type relates to each other (i.e. Director references Film through field films, Film references Actor through field actors), the GraphQL server can easily convert the data into the expected tree shape:
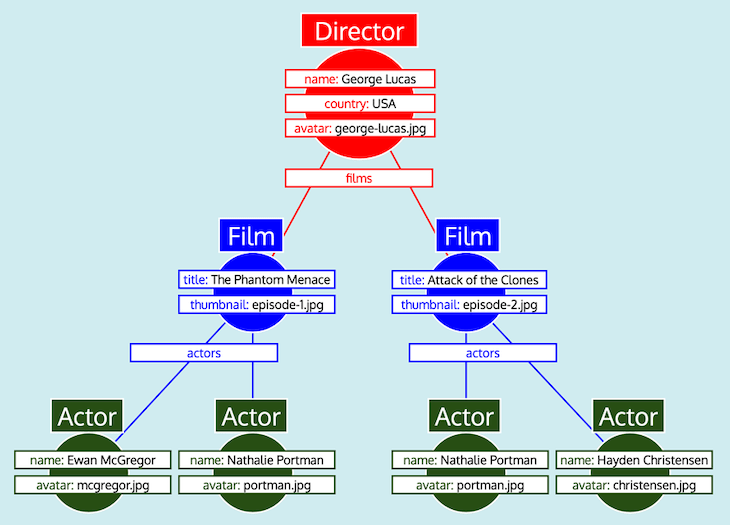
Finally, the GraphQL server outputs the tree, which has the shape of the expected response:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analyzing the time complexity of the solution
Let's analyze the big O notation of the data-loading algorithm to understand how the number of queries executed against the database grows as the number of inputs grows, to make sure that this solution is performant.
The data-loading engine loads data in iterations corresponding to each type. By the time it starts an iteration, it will already have the list of all the IDs for all the objects to fetch, hence it can execute 1 single query to fetch all the data for the corresponding objects. It then follows that the number of queries to the database will grow linearly with the number of types involved in the query. In other words, the time complexity is O(n), where n is the number of types in the query (however, if a type is iterated more than once, then it must be added more than once to n).
This solution is very performant, much better than the exponential complexity expected from dealing with graphs, or logarithmic complexity expected from dealing with trees.
Implemented PHP code
The data-loading process takes place on function getComponentData from class Engine in package Component Model.